Live Job JSON Integration
This section describes the JSON data format for publishing Jobs using the live flow.
UniqueID flow
Note: the
uniqueidfeature requires Tunnel v1.70 or higher.
When publishing your live job and finish jobs, mark them with a "uniqueid" string field.
This flow allows simple matching of live → finish jobs, as it is just a single field to match.
- This flow also optionally allows changing of all job fields:
start_time,jobdir,seed,config, etc. (as long asuniqueidremains the same)
UniqueID Examples
uniqueid can contain any string value. Examples:
| UniqueID | Description |
|---|---|
"ca8d8738-d8a0-4ad3-b0aa-09af0ff87caf" | UUID |
"12345678" | Queue ID |
"071172a6ea81cbd39114b" | SHA/hash |
"1" | Simple job counter (with a regression) |
"this-is-a-unique-key1/42" | Arbitrary string |
"job-12345" |
Uniqueness within a Regression
Unique ID only needs to be unique within a single Regression.
- You can re-use the same
uniqueidin a different regression.
Required Job Fields for Unique ID flow
To publish a job using uniqueid, there are only 2 fields required:
categoryuniqueid
UniqueID JSON Flow
To publish a single Job via uniqueid flow, you need to publish 2 separate JSON objects:
- When the job is submitted (or when it starts), publish a
liveJSON, with auniqueid. - At some point in the future, when the job finishes (either pass or fail), publish a
finishJSON, with the sameuniqueidvalue.
Example Minimal UniqueID JSON
This Job is an example of a live simulation using uniqueid.
Minimal JSON example when publishing a live job (you can have more fields if desired):
{
"category": "sim",
"uniqueid": "ca8d8738-d8a0-4ad3-b0aa-09af0ff87caf",
"result": "live"
}
Example Full UniqueID JSON
{
"start_time": "2025-02-01T02:00:11.123-05:00",
"uniqueid": "ca8d8738-d8a0-4ad3-b0aa-09af0ff87caf",
"jobdir": "/home/runs/myregr/2/job-3",
"category": "sim",
"config": "sim +rand +tbuf +seed=123",
"seed": "123",
"build": "mybuild",
"testgroup": "mytestgroup",
"metadata": [
[
"bufsize",
"9902"
]
],
"result": "live"
}
UniqueID Finish JSON
When the job is complete, publish a finish message (either pass or fail):
- Note: this must have the same
uniqueidvalue, so that Simscope can match it.
{
"start_time": "2025-02-01T02:00:11.123-05:00",
"compute_ms": 204825,
"uniqueid": "ca8d8738-d8a0-4ad3-b0aa-09af0ff87caf",
"jobdir": "/home/runs/myregr/2/job-3",
"category": "sim",
"config": "sim +rand +tbuf +seed=123",
"seed": "123",
"build": "mybuild",
"testgroup": "mytestgroup",
"metadata": [
[
"bufsize",
"9902"
]
]
"fail_message": "Store buffer underflow at top.fifo1.input2[3]",
"result": "fail"
}
Publishing Live Jobs to Simscope
To publish, use a job-live message via the Tunnel client:
# NOTE: replace [myrun/123] with your regression name and [job.json] with your live job JSON file
> simscope-tunnel --config=simscope-tunnel.conf --publish job-live --regression=myrun/123 job.json
Notes on Live Jobs
A few notes (limitations) on Live jobs:
- Live jobs do not capture statistics into their parent regression: cycles, runtime, etc.
- When Live jobs finish, the statistics will be computed into the regression.
- Also, Live jobs cannot be charted (until they finish).
- Live jobs are not fails, so they can not be assigned, nor can they have Rules.
- Simscope allows both live and normal regressions simultaneously.
- When transitioning from a Live job → Finished job, the JSON uniqueid field must match.
- Simscope uses the input fields from the finished job to find and delete the live job automatically.
- If the
uniqueidchanges (or is omitted), Simscope will not remove thelivejob.
- You can publish multiple live updates on a single job. For example, you can publish metadata or other status fields as the job is running.
- Unfinished live jobs automatically get pruned from the database after 7 days.
Example Message flow for a full Regression containing Live Jobs
Here is an example flow for publishing one Regression containing five Jobs, with Live Job tracking.
→ This requires 12 JSON messages:
- 1
regr-start - 5
job-live - 5
job-finish - 1
regr-finish
JSON Message Summary:
1. Publish regr-start — Regression will show as LIVE
2. Publish job-live — Job #1 started
3. Publish job-live — Job #2 started
4. Publish job-live — Job #3 started
5. Publish job-live — Job #4 started
6. Publish job-live — Job #5 started
7. Publish job-finish — after Job #1 finishes
8. Publish job-finish — after Job #2 finishes
9. Publish job-finish — after Job #3 finishes
10. Publish job-finish — after Job #4 finishes
11. Publish job-finish — after Job #5 finishes
12. Publish regr-finish — Regression will show as complete
Regression Live Job Timeout (automatic kill jobs)
If livetimeoutsignature is enabled in simscope.config,
and a regression either hits timeout or finishes with pending Live Jobs, these jobs
will be migrated intto a fail signature automatically.
-
This is equivalent to automatically killing the pending jobs.
-
Note: Tank Regression is a manual mechanism to kill or hide a regression.
Here is an example regression that timed out, with livetimeoutsignature enabled
(note this shows up as an Aborted regression):
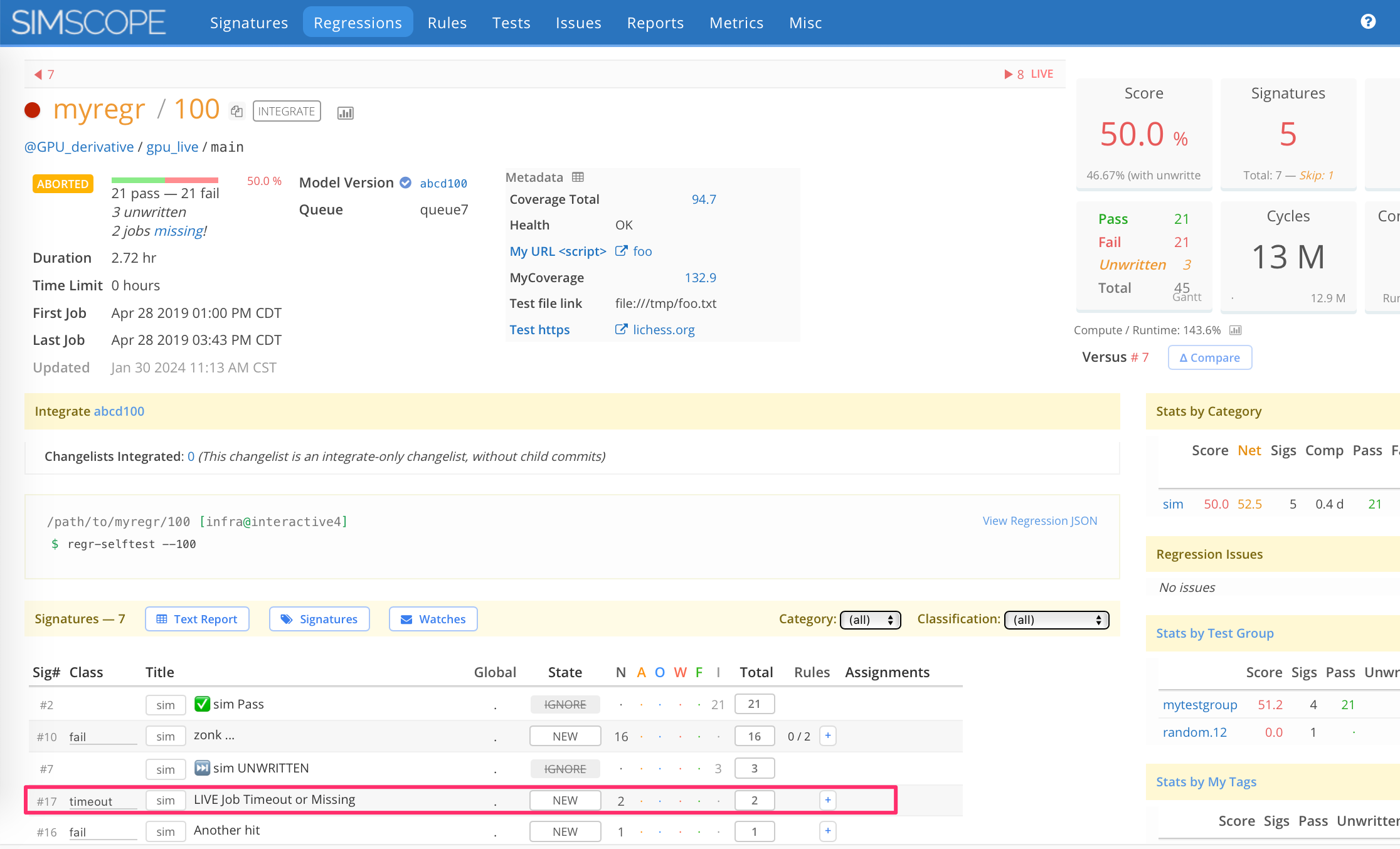
Old: Required Job Fields (Job key instead of Unique ID)
Note: this section is obsolete, as
uniqueidis a better flow.
The following fields cannot change between a live job and a finish job:
start_timecategoryjobdirseedconfig
These fields are used to determine the job key (unique identifier), so they must remain the same in their live and finish messages.
Old: Example Live JSON
This Job is an example of a live simulation.
{
"start_time": "2025-05-07T02:00:11.123-05:00",
"jobdir": "/home/runs/myregr/2/job-3",
"category": "sim",
"config": "sim +rand +tbuf +seed=123",
"seed": "123",
"build": "mybuild",
"testgroup": "mytestgroup",
"result": "live"
}
- NOTE: you can optionally have other fields in the live JSON, like
"host".